What is UnAV-100?

We explore the problem of dense-localizing audio-visual events:
recognizing and localizing all audio-visual events occurring in an untrimmed video.
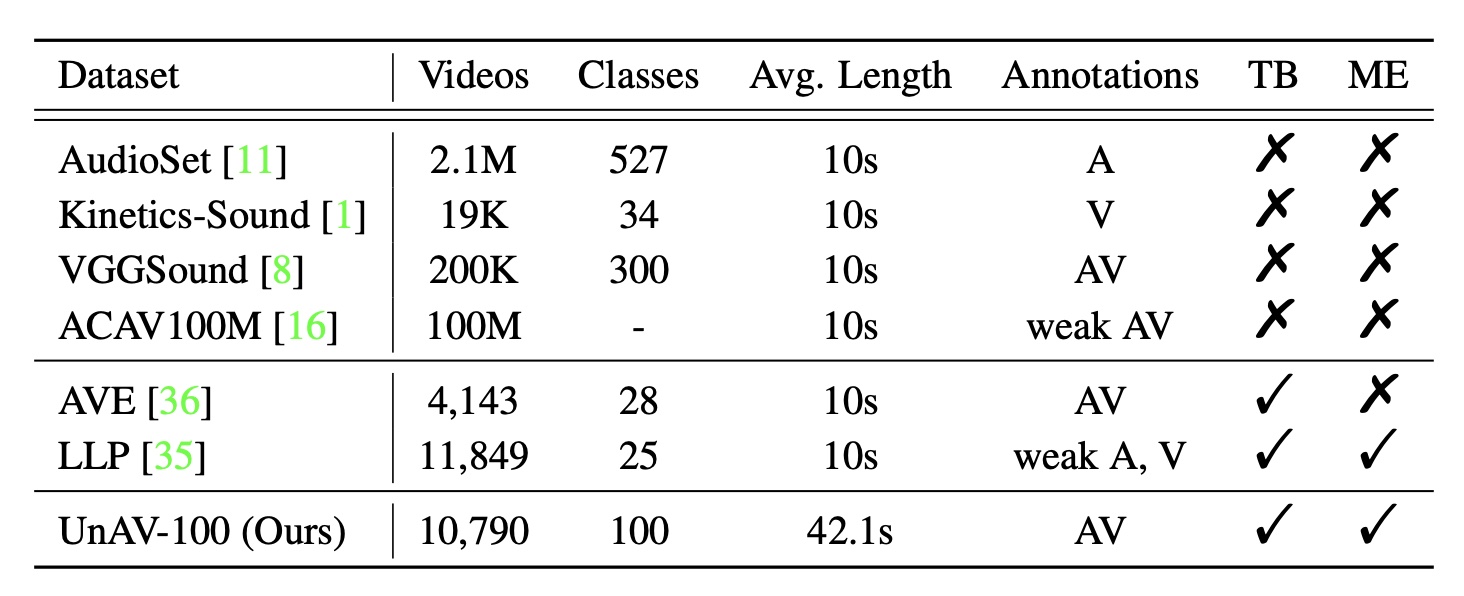
We contribute UnAV-100 as the first audio-visual dataset based on untrimmed videos. Different from the previous AVE dataset, our UnAV-100 consists of more than
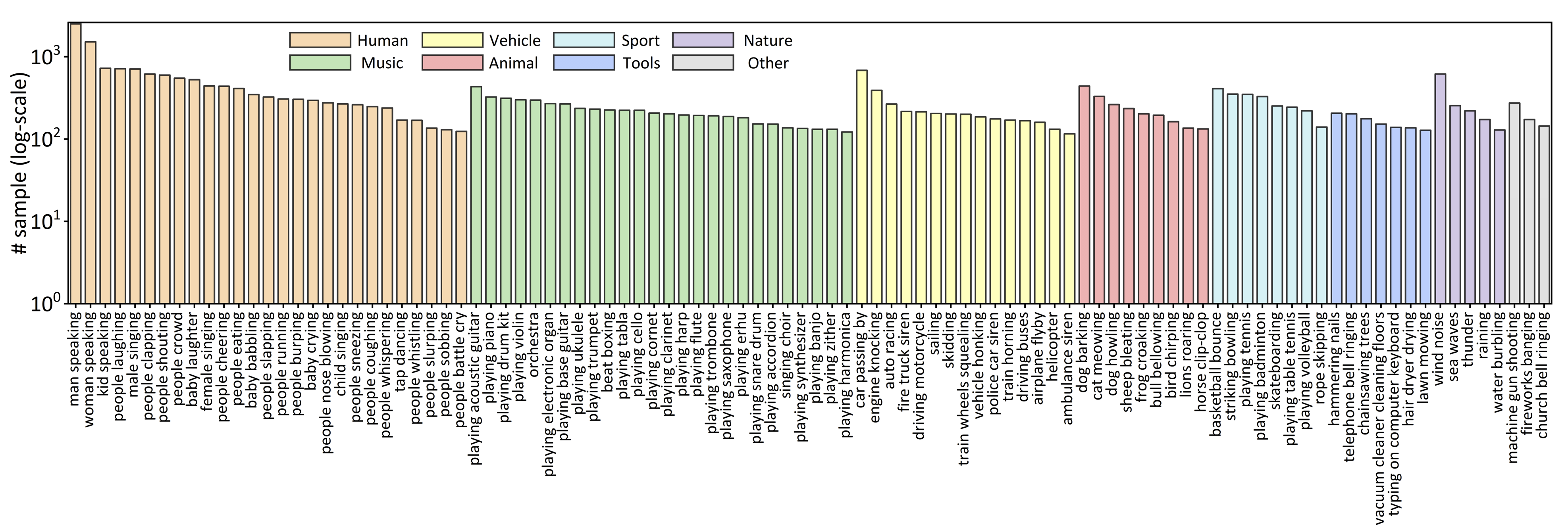
10K untrimmed videos with over 30K audio-visual events covering 100 different event categories.
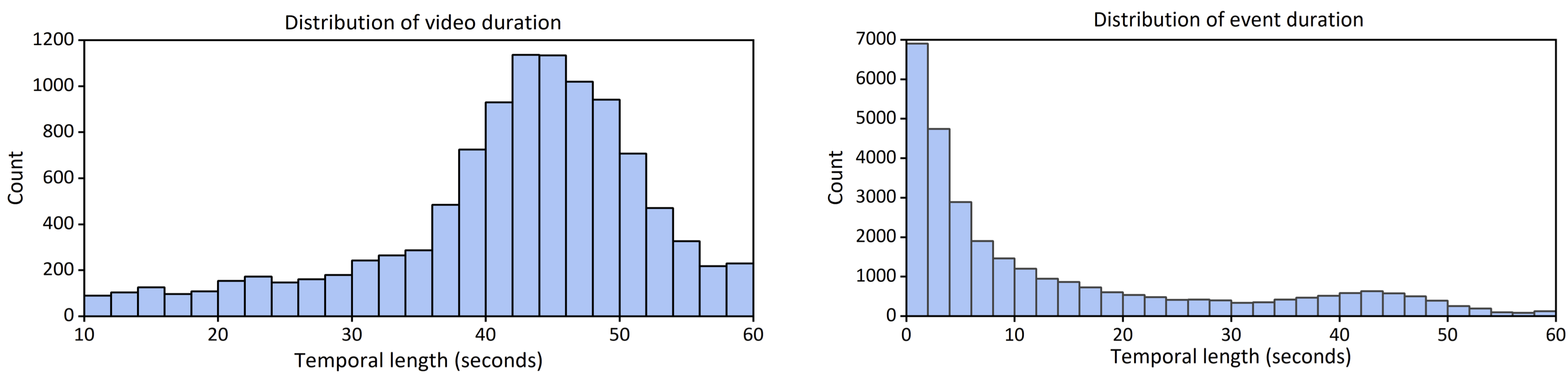
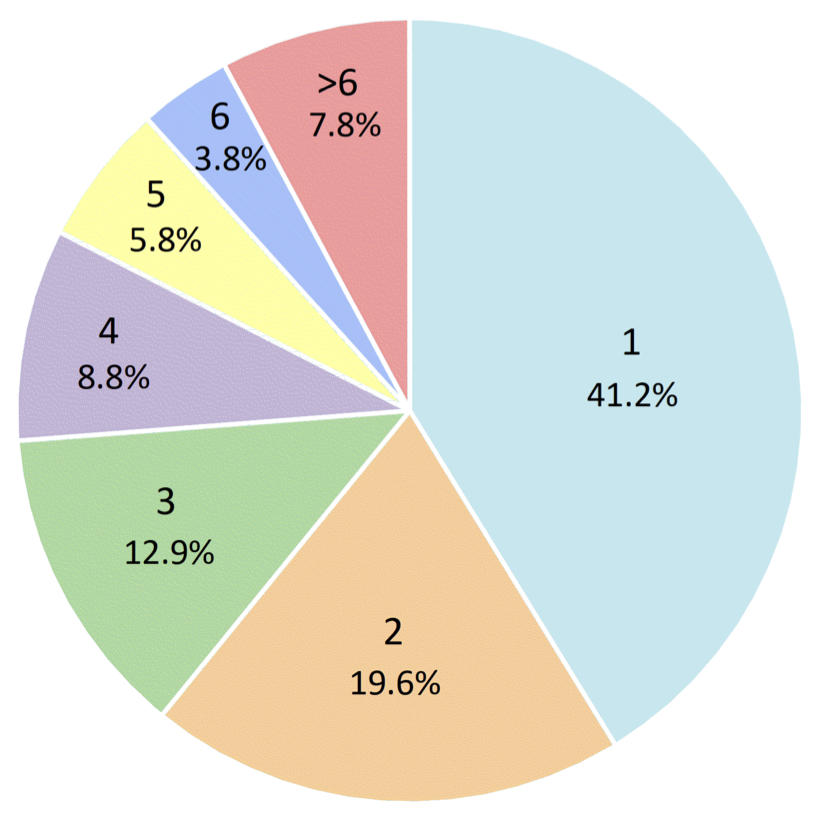
There are often multiple audio-visual events that might be very short or long, and occur concurrently in each video as in real-life audio-visual scenes.
We believe our UnAV-100, with its realistic complexity, can promote the exploration on comprehensive audio-visual video understanding.
We explore the problem of dense-localizing audio-visual events: recognizing and localizing all audio-visual events occurring in an untrimmed video.
We contribute UnAV-100 as the first audio-visual dataset based on untrimmed videos. Different from the previous AVE dataset, our UnAV-100 consists of more than 10K untrimmed videos with over 30K audio-visual events covering 100 different event categories. There are often multiple audio-visual events that might be very short or long, and occur concurrently in each video as in real-life audio-visual scenes. We believe our UnAV-100, with its realistic complexity, can promote the exploration on comprehensive audio-visual video understanding.